




3D立体ペーパー 切絵シリーズ
去る9月17日(火)、マイドーム大阪4階セミナー室にて「ORIST技術セミナーBMB第46回勉強会」が盛況に開催されました。
テーマは、「AI・IoTに関する契約実務の最前線と知財戦略」~AI技術とIoT技術を契約と知財で守るための戦略とは~。
内田 誠弁護士・弁理士(iCraft法律事務所)によるAI・IoTに特化した知財セミナーは、かなり専門的な内容でしたが、40名の定員を上回る参加となり、企業の知財担当者の関心を十二分に満足させる内容でした。

また、今回の勉強会では、sli.do(スライドゥ)という質疑応答サービスを活用し、講師への質問を匿名かつリアルタイムで受け付けることができ、スムーズに質疑応答が執り行われたように思います。
さて、勉強会では最初に、AI開発の基礎知識と学習済みモデル開発ついて、解釈につまづきやすい点を取り上げました。
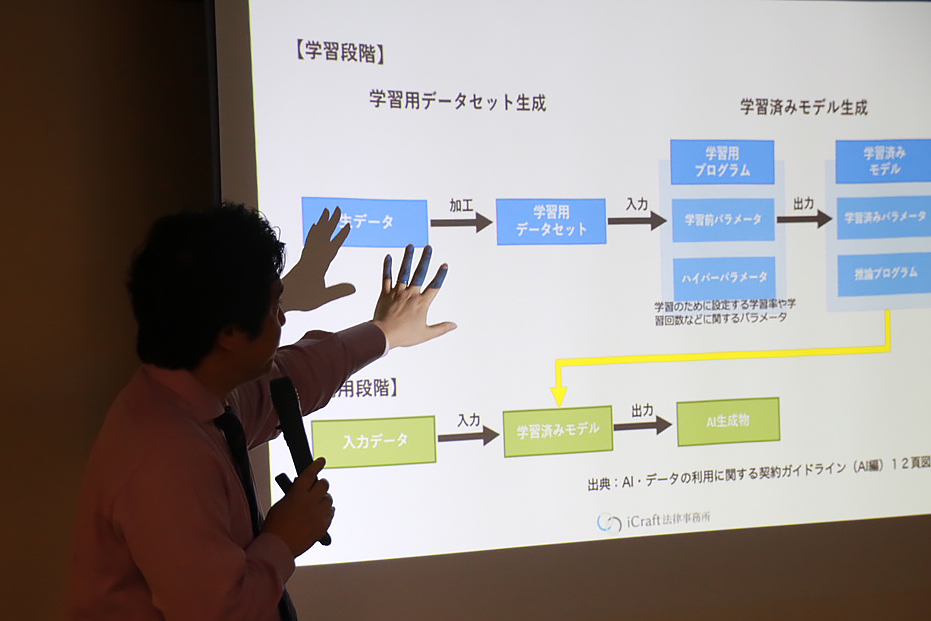
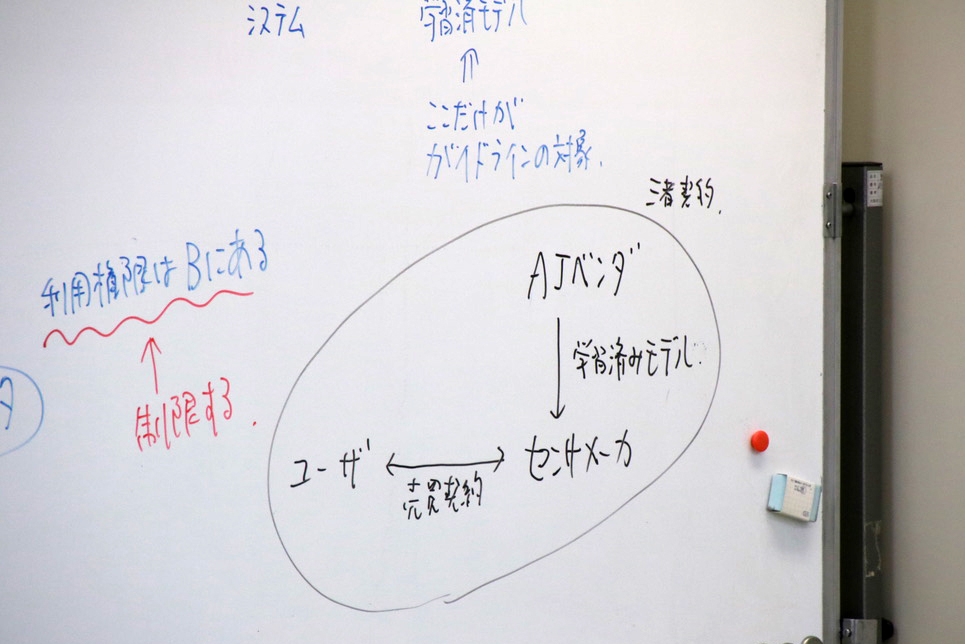
例えば、システム全体を開発する場合に、「学習済みモデルだけを外部のAIベンダーに発注するパターン」では、ガイドラインで契約時の「ユーザー」と書かれているところは「ベンダー」になります。
システム開発で、ユーザーとAIベンダーの間にSIerが入り、SIerがシステム開発全般、ベンダーが学習済みの発注を受けている場合、AI契約ガイドラインが図の範囲(下写真)だけを対象にしているため、ガイドラインのいう「ユーザー」は「SIer」になります。

次にAI開発特有の問題点の話に入りました。AI開発は、普通のシステム開発と違って、ユーザーデータの重要性(利害)、性能保証の困難性、ノウハウ・データセット・学習済みモデルの重要性と利害関係(横展開需要や知財戦略)が主要な問題となります。
従来のシステム開発のように一括契約でやってしまうと、お金を払ったのに何もできないという事にもなります。
従って、開発の中身を見ながら徐々に作っていくしかない。開発プロセスの契約をフェーズ毎に分割すべきだという話になります。
このため、経産省の「AIデータ契約ガイドライン」が推奨しているのは、「1.アセスメント」、「2.PoC」
、「3.開発」、「4.追加学習」の4段階に分けた開発プロセスの契約です。
この4つの段階に対し、「1.学習済みモデルだけを開発するケース」、「2.システムとして開発を依頼するケース」それぞれのケースに対して、開発の流れと契約の説明がありました。
次に、IoTに関連する注意点や具体的な法的問題点の話がありました。
データを提供する際の注意点として、まずはデータを提供する前に交わす契約によって自由な利用を制限することの重要性、データオーナーシップの話がありました。
その上で、法律、知財双方の観点からデータ提供において定めるべき契約条件の話がありました。

そして実際にデータを提供する場面での注意点として、どこまでデータを提供したら良いのか、そして、エッジAI(IoT端末で実施されるAI処理)を用いる場合の利点と注意点の話については、契約を三者契約にした方がよいといった話などが聞けました。
また、データを取得する際の注意点として、コンタミネーション(秘密漏洩)をどのようにして避けるべきか、さらに個人情報の取り扱いにおける法的なお話がありました。
続いて、アセスメント段階の法的問題点の話に入り、契約書で記載漏れがちな項目として、パソコン内のバックアップデータの取り扱いや、秘密情報に基づいて創出された知的財産権の話などがありました。
また、秘密保持契約と開発契約の不一致における問題と対策の話などもありました。
PoC段階では、ノウハウの注意点やPoC貧乏の話などがありました。例えば、ノウハウは営業秘密にかかる権利に該当するので、知的財産権から除外しておかないとユーザーに帰属してしまうということがよくあるといった契約上の注意点です。

開発段階の話では、製品に問題が発生した時にAIシステム開発のどこで問題が発生したかの特定が困難という話や、性能保証の問題に対する契約の結び方の話がありました。
さらに、この段階における知財面での法的問題点の話がありました。
学習済みモデルの著作権も特許発明もベンダーの帰属にして、ユーザーには通常実施権のみを施すというやり方においては、ユーザー側にすると、競合他社にライセンス提供されたら困るという問題があります。
そういうケースでどう契約を交わして双方に利のある対策を講じるのかの話がありました。
また、知的財産権侵害を主張される場合に対し、ユーザーとベンダー、双方の責任の割り振りを契約書上どう書くのかという話もありました。

最後は知財戦略の話として、広範囲に権利を取るための書き方の工夫などを交えながら、AI関連発明にどのようなものがあるかの具体例が詳細に示されました。
また、守りの特許という観点から、一見意味がないように思われる学習済みモデルの出願の場合においても、自社製品が他社から特許権の侵害だと言われるのを防ぐという意味で権利化を図る戦略の話が出ました。
次にどのようにしたら権利を取りやすいか、どれくらいの話だったら取りやすいか、広く取れるか?という話と、どうすればいかに侵害立証がしやすいかという権利行使の話がありました。
また、出願されている権利範囲に自社の事業モデルが含まれておらず、意味のない特許出願が放置されるに至っている問題の話とそうならないための出願戦略の話がありました。
具体的に知財戦略をどう構築していくのかという話では、チームの構成の仕方、割り振り、打ち合わせの頻度、何を決めなければならないか、そのタイミングなどについて説明がありました。具体例の中では弁護士はどういう書類を作成する必要があったのか、弁理士はどういう特許出願を行なったのかという話が出てきました。

その他、ユーザーがベンダーに開発を委託する場合でも、民法ではユーザーに権利があるとは規定されていないため、ベンダーサイドは(契約時に)戦ってほしいという小話などが挟まれていました。
以上、今回は一貫して法律、および知財戦略、さらには企業コンプライアンス(炎上リスク含む)の視点から、包括的かつ具体的にコンピュータプログラムを守るための勉強会となりました。






